Bard vs ChatGPT vs Claude
Araştırmacılar, tespitin aynı eğitim ve veri kümelerinden yararlanması nedeniyle bir yapay zeka modelinin kendi içeriğini kendi kendine tespit etme avantajına sahip olabileceği fikrini test etti. Bulmayı beklemedikleri şey, test ettikleri üç yapay zeka modelinden birinin ürettiği içeriğin o kadar tespit edilemez olduğu ve onu üreten yapay zekanın bile tespit edemediğiydi.
Çalışma, Southern Methodist Üniversitesi Lyle Mühendislik Okulu Bilgisayar Bilimleri Bölümü’nden araştırmacılar tarafından yürütüldü.
Yapay Zeka İçerik Tespiti
Birçok AI dedektörü, AI tarafından oluşturulan içeriğin açıklayıcı sinyallerini aramak üzere eğitilmiştir. Bu sinyallere, temel transformatör teknolojisi nedeniyle üretilen “yapılar” adı verilir. Ancak diğer eserler her temel modele (Yapay Zekanın dayandığı Büyük Dil Modeli) benzersizdir.
Bu yapılar her yapay zeka için benzersizdir ve bir yapay zeka modelinden diğerine her zaman farklı olan ayırt edici eğitim verilerinden ve ince ayardan kaynaklanırlar.
Araştırmacılar, bir yapay zekanın, farklı bir yapay zeka tarafından oluşturulan içeriği tanımlamaya çalışmaktan önemli ölçüde daha iyi bir şekilde, kendi içeriğini tanımlama konusunda daha büyük bir başarıya sahip olmasını sağlayan şeyin bu benzersizlik olduğuna dair kanıtlar keşfettiler.
Bard’ın, Bard tarafından oluşturulan içeriği tanımlama şansı daha yüksektir ve ChatGPT’nin, ChatGPT tarafından oluşturulan içeriği tanımlama konusunda daha yüksek bir başarı oranı vardır, ancak…
Araştırmacılar bunun Claude tarafından oluşturulan içerik için doğru olmadığını keşfettiler. Claude bunun oluşturduğu içeriği tespit etmekte zorluk yaşadı. Araştırmacılar, Claude’un kendi içeriğini neden tespit edemediğine dair bir fikir paylaştılar ve bu makalede bu konu daha ileride tartışılacaktır.
Araştırma testlerinin ardındaki fikir şu:
“Her model farklı şekilde eğitilebildiğinden, olası tüm üretken yapay zeka araçlarının yarattığı eserleri tespit edecek tek bir algılama aracı oluşturmak zor.
Burada, kendi kendini algılama adı verilen farklı bir yaklaşım geliştiriyoruz; burada, kendi ürettiği metni insan tarafından yazılan metinden ayırmak amacıyla kendi yapıtlarını tespit etmek için üretken modelin kendisini kullanıyoruz.
Bu, tüm üretken yapay zeka modellerini tespit etmeyi öğrenmemize gerek kalmaması avantajına sahip olabilir, ancak algılama için yalnızca üretken bir yapay zeka modeline erişmemiz gerekiyor.
Sürekli olarak yeni modellerin geliştirildiği ve eğitildiği bir dünyada bu büyük bir avantaj.”
Metodoloji
Araştırmacılar üç yapay zeka modelini test etti:
- OpenAI’den ChatGPT-3.5
- Google’dan Bard
- Antropik tarafından Claude
Kullanılan tüm modeller Eylül 2023 versiyonlarıydı.
Elli farklı konudan oluşan bir veri seti oluşturuldu. Her bir AI modeline, üç AI modelinin her biri için elli makale oluşturan elli konunun her biri için yaklaşık 250 kelimelik makaleler oluşturması için tam olarak aynı yönlendirmeler verildi.
Daha sonra her yapay zeka modelinden aynı şekilde kendi içeriğini yeniden ifade etmesi ve her orijinal makalenin yeniden yazılması olan ek bir makale üretmesi istendi.
Ayrıca elli konunun her biri hakkında insan yapımı elli makale topladılar. İnsanların ürettiği makalelerin tümü BBC’den seçilmiştir.
Araştırmacılar daha sonra yapay zeka tarafından oluşturulan içeriği kendi kendine tespit etmek için sıfır atış yönlendirmesini kullandı.
Sıfır atışlı yönlendirme, yapay zeka modellerinin özel olarak eğitim almadıkları görevleri tamamlama becerisine dayanan bir tür yönlendirmedir.
Araştırmacılar ayrıca metodolojilerini açıkladılar:
“Her yapay zeka sisteminin başlattığı ve belirli bir sorguyla oluşturduğu yeni bir örneğini oluşturduk: ‘Aşağıdaki metin, yazım düzeni ve sözcük seçimiyle eşleşiyorsa.’ Prosedür:
orijinal, başka kelimelerle yazılmış ve insan makaleleri için tekrarlanır ve sonuçlar kaydedilir.Ayrıca AI tespit aracı ZeroGPT’nin sonucunu da ekledik. Bu sonucu performansı karşılaştırmak için değil, tespit görevinin ne kadar zorlu olduğunu göstermek için bir temel olarak kullanıyoruz.”
Ayrıca, %50’lik bir doğruluk oranının tahmin etmeye eşit olduğunu ve bunun esasen bir başarısızlık olan doğruluk düzeyi olarak kabul edilebileceğini de belirttiler.
Sonuçlar: Kendini Algılama
Araştırmacıların örneklem oranlarının düşük olduğunu kabul ettiklerini ve sonuçların kesin olduğuna dair bir iddiada bulunmadıklarını da belirtelim.
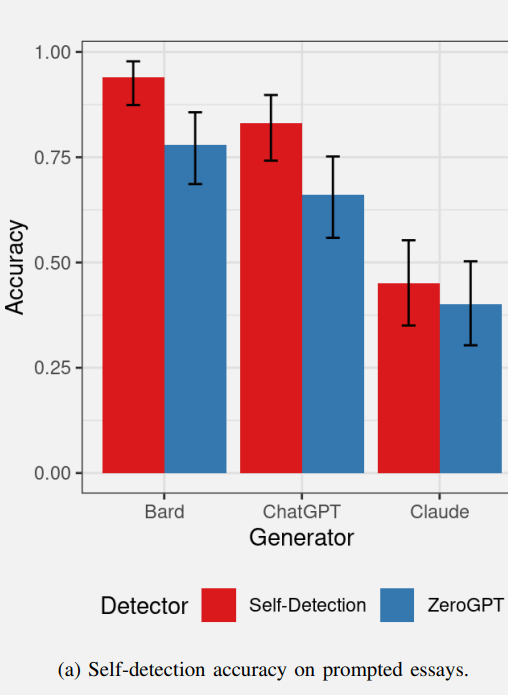
Aşağıda, ilk makale grubunun yapay zekanın kendi kendini tespit etmesinin başarı oranlarını gösteren bir grafik bulunmaktadır. Kırmızı değerler yapay zekanın kendi kendini algılamasını, mavi ise yapay zeka algılama aracı ZeroGPT’nin ne kadar iyi performans gösterdiğini temsil ediyor.
Yapay Zekanın Kendi Metin İçeriğini Kendiliğinden Algılamasının Sonuçları
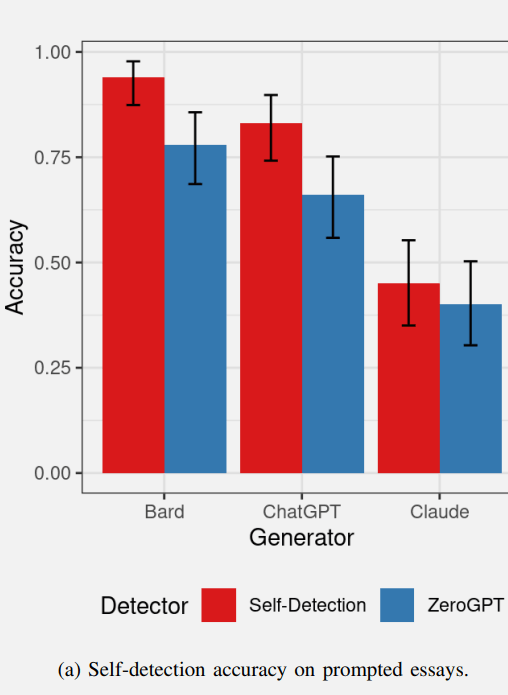
Bard kendi içeriğini tespit etmede oldukça başarılıydı ve ChatGPT de kendi içeriğini tespit etmede benzer şekilde iyi performans gösterdi.
Yapay zeka tespit aracı ZeroGPT, Bard içeriğini çok iyi tespit etti ve ChatGPT içeriğini tespit etmede biraz daha düşük performans gösterdi.
ZeroGPT, Claude tarafından oluşturulan içeriği tespit etmekte esasen başarısız oldu ve %50 eşiğinden daha kötü performans gösterdi.
Claude, kendi içeriğini kendi kendine tespit edemediği ve Bard ve ChatGPT’den önemli ölçüde daha kötü performans gösterdiği için grubun dışında kalan kişiydi.
Araştırmacılar, Claude’un çıktısının daha az tespit edilebilir eserler içerebileceğini öne sürdüler; bu da hem Claude hem de ZeroGPT’nin neden Claude makalelerini yapay zeka tarafından üretilmiş olarak tespit edemediğini açıkladı.
Dolayısıyla, Claude kendi içeriğini güvenilir bir şekilde kendi kendine tespit edemese de, bunun, Claude’un çıktısının, daha az yapay zeka eseri çıktısı açısından daha yüksek kalitede olduğunun bir işareti olduğu ortaya çıktı.
ZeroGPT, Bard tarafından oluşturulan içeriği tespit etmede, ChatGPT ve Claude içeriğini tespit etmede olduğundan daha iyi performans gösterdi. Araştırmacılar, Bard’ın daha fazla tespit edilebilir eser üreterek Bard’ın tespit edilmesini kolaylaştırdığını öne sürdü.
Yani kendi kendini algılayan içerik açısından Bard daha fazla tespit edilebilir yapıt üretiyor olabilir ve Claude daha az yapay oluşum üretiyor olabilir.
Sonuçlar: Kendi Kendini Algılayan Başka Sözlerle Anlatılan İçerik
Araştırmacılar, yapay zeka modellerinin kendi başka sözcüklerle ifade edilmiş metinlerini otomatik olarak algılayabileceğini, çünkü model tarafından oluşturulan eserlerin (orijinal makalelerde tespit edildiği gibi) yeniden yazılan metinde de mevcut olması gerektiğini öne sürdüler.
Ancak araştırmacılar, metni yazma ve başka sözcüklerle ifade etme istemlerinin farklı olduğunu, çünkü her yeniden yazmanın orijinal metinden farklı olduğunu, bunun da sonuç olarak başka sözcüklerle ifade edilen metnin kendi kendini algılaması için farklı bir kendini algılama sonuçlarına yol açabileceğini kabul etti.
Başka kelimelerle ifade edilen metnin kendi kendini algılamasının sonuçları, orijinal makale testinin kendi kendini algılamasından gerçekten farklıydı.
- Bard, başka sözcüklerle ifade edilen içeriği benzer bir oranda kendi kendine tespit edebildi.
- ChatGPT, başka kelimelerle ifade edilen içeriği %50 oranından (tahmin etmeye eşdeğer) çok daha yüksek bir oranda kendi kendine tespit edemedi.
- ZeroGPT performansı önceki testteki sonuçlara benzerdi ve biraz daha kötü performans gösterdi.
Belki de en ilginç sonuç Anthropic’ten Claude tarafından elde edildi.
Claude, başka kelimelerle ifade edilen içeriği kendi kendine tespit edebildi (ancak önceki testte orijinal makaleyi tespit edemedi).
Claude’un orijinal makalelerinde yapay zekanın ürettiğini işaret edecek kadar az eser bulunması ve Claude’un bile bunu tespit edememesi ilginç bir sonuç.
Ancak ZeroGPT bunu başaramamışken, açıklamayı kendi kendine tespit edebildi.
Araştırmacılar bu teste dikkat çekti:
“Başka kelimelerle ifade etmenin ChatGPT’nin kendi kendini algılamasını engellerken Claude’un kendi kendini algılama yeteneğini arttırdığının bulunması çok ilginç ve bu iki transformatör modelinin iç işleyişinin bir sonucu olabilir.”
Yapay Zekayla Başka Sözcüklerle Anlatılan İçeriğin Kendi Kendini Algılama Ekran Görüntüsü
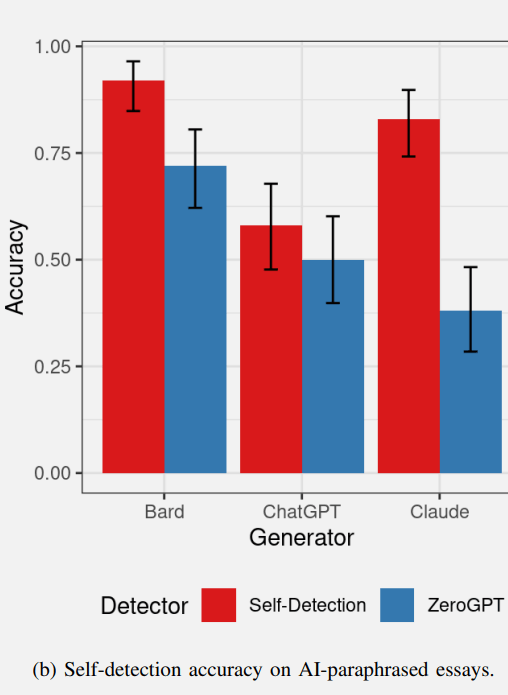
Bu testler, özellikle Anthropic’in Claude’u ile ilgili olarak neredeyse öngörülemeyen sonuçlar verdi ve bu eğilim, yapay zeka modellerinin birbirlerinin ilginç bir kırışıklığa sahip içeriklerini ne kadar iyi algıladığının test edilmesiyle devam etti.
Sonuçlar: Birbirlerinin İçeriklerini Algılayan Yapay Zeka Modelleri
Bir sonraki test, her bir AI modelinin, diğer AI modelleri tarafından oluşturulan içeriği tespit etmede ne kadar iyi olduğunu gösterdi.
Bard’ın diğer modellere göre daha fazla yapı ürettiği doğruysa diğer modeller Bard tarafından oluşturulan içeriği kolayca tespit edebilecek mi?
Sonuçlar evet, Bard tarafından oluşturulan içeriğin diğer yapay zeka modelleri tarafından tespit edilmesi en kolay içerik olduğunu gösteriyor.
ChatGPT tarafından oluşturulan içeriğin tespit edilmesiyle ilgili olarak, hem Claude hem de Bard, bunun yapay zeka tarafından oluşturulduğunu tespit edemedi (Claude’un bunu tespit edememesi gibi).
ChatGPT, Claude tarafından oluşturulan içeriği hem Bard hem de Claude’dan daha yüksek bir oranda tespit edebildi ancak bu yüksek oran, tahmin etmekten pek de iyi değildi.
Buradaki bulgu, hepsinin birbirlerinin içeriklerini tespit etmede o kadar da iyi olmadığıydı; araştırmacılar bunun, kendi kendini tespit etmenin umut verici bir çalışma alanı olduğunu gösterebileceğini düşündü.
İşte bu spesifik testin sonuçlarını gösteren grafik:
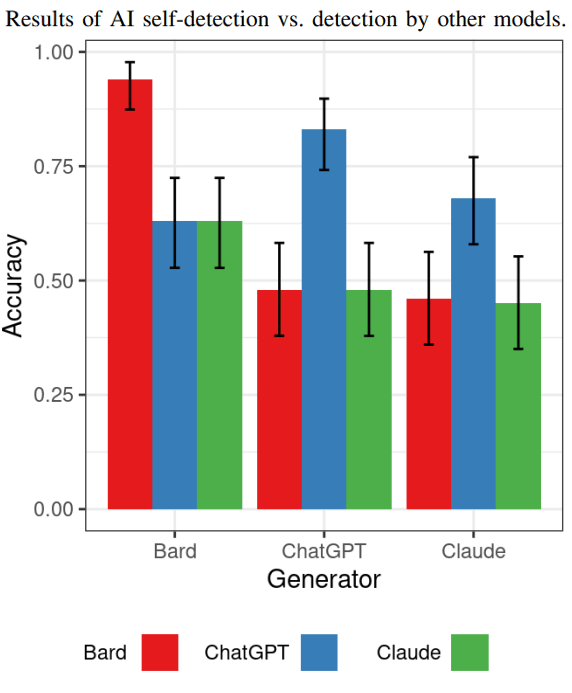
Bu noktada araştırmacıların bu sonuçların genel olarak yapay zeka tespiti konusunda kesin olduğunu iddia etmediklerini belirtmekte fayda var. Araştırmanın odak noktası, yapay zeka modellerinin kendi oluşturdukları içerikleri kendi kendine tespit etme konusunda başarılı olup olamayacağını test etmekti. Cevap çoğunlukla evet, kendi kendini tespit etme konusunda daha iyi iş çıkarıyorlar ancak sonuçlar ZEROGpt ile bulunanlara benzer.
Araştırmacılar şu yorumu yaptı:
“Kendini algılama, ZeroGPT’ye kıyasla benzer bir algılama gücü gösteriyor, ancak bu çalışmanın amacının, kendi kendini algılamanın diğer yöntemlerden üstün olduğunu iddia etmek olmadığını unutmayın; bu, birçok mevcut durumla karşılaştırmak için büyük bir çalışma gerektirir. art AI içerik algılama araçları. Burada yalnızca modellerin temel kendini algılama yeteneğini araştırıyoruz.”
Sonuçlar ve Çıkarımlar
Testin sonuçları, yapay zeka tarafından oluşturulan içeriği tespit etmenin kolay bir iş olmadığını doğruluyor. Bard kendi içeriğini ve başka kelimelerle ifade edilen içeriği tespit edebilir.
ChatGPT kendi içeriğini algılayabilir ancak başka kelimelerle ifade edilen içerik üzerinde daha az iyi çalışır.
Claude öne çıkıyor çünkü kendi içeriğini güvenilir bir şekilde kendi kendine tespit edemiyor ancak başka kelimelerle ifade edilen içeriği tespit edebildi ki bu da biraz tuhaf ve beklenmedik bir durumdu.
Claude’un orijinal makalelerini ve başka kelimelerle yazılmış makaleleri tespit etmek ZeroGPT ve diğer yapay zeka modelleri için zorlu bir işti.
Araştırmacılar Claude sonuçları hakkında şunları kaydetti:
“Bu görünüşte sonuçsuz sonuç, birbiriyle ilişkili iki nedenden kaynaklandığı için daha fazla dikkate alınması gerekiyor.
1) Modelin çok az tespit edilebilir yapaylık içeren metin oluşturma yeteneği. Bu sistemlerin amacı insan benzeri metinler oluşturmak olduğundan, tespit edilmesi zor olan daha az yapay yapı, modelin bu hedefe yaklaşması anlamına gelir.
2) Modelin kendi kendini algılama yeteneği, kullanılan mimariden, istemden ve uygulanan ince ayardan etkilenebilir.”
Araştırmacıların Claude hakkında başka bir gözlemi daha vardı:
“Yalnızca Claude tespit edilemiyor. Bu, Claude’un diğer modellere göre daha az tespit edilebilir artefakt üretebileceğini gösterir.
Kendini algılamanın tespit oranı da aynı eğilimi takip ediyor; bu da Claude’un daha az yapaylık içeren metinler oluşturduğunu ve bunun insan yazısından ayırt edilmesini zorlaştırdığını gösteriyor”.
Ancak elbette işin tuhaf tarafı, daha yüksek başarı oranına sahip diğer iki modelin aksine Claude’un kendi orijinal içeriğini kendi kendine tespit edememesiydi.
Araştırmacılar, kendi kendini algılamanın devam eden araştırmalar için ilginç bir alan olmaya devam ettiğini belirtti ve daha fazla çalışmanın, daha fazla yapay zeka tarafından oluşturulan metin çeşitliliğine sahip daha büyük veri kümelerine odaklanabileceğini, ek yapay zeka modellerini test edebileceğini, daha fazla yapay zeka dedektörüyle karşılaştırma yapabileceğini ve son olarak da bu konuda çalışmayı önerdiler. hızlı mühendisliğin algılama seviyelerini ne kadar etkileyebileceği.
Orijinal araştırma makalesini ve özetini buradan okuyun:
Transformatör Tabanlı Büyük Dil Modelleri için Yapay Zeka İçerik Kendini Algılama
Shutterstock/SObeR 9426’dan Öne Çıkan Görsel